SQL Server Window Function OVER(PARTITION BY)
In the previous post, we had seen the simplest implementation of the Window Functions: an aggregate function with an empty bracket OVER() clause, which meant the Window consisted of all the rows in the query result. In this post, we will look at how to define row sets for the Window Functions with PARTITION BY part. We will be seeing, how to change that Window. We will use the same dummy tables and dataset as the previous post.
In a basic sense, PARTITION BY divides the query result sets into partitions or groupings we defined. And for each partition Window Functions are applied separately and operated.
Syntax:- Syntax for the PARTITION BY part of the OVER() clause is below.
OVER(PARTITION BY Column1, Column2, Column3, … ColumnN)
In the OVER(), after the PARTITION BY part, we provide the list of columns we would use to group the result sets. It computes for the entire group while keeping the individual row identities intact. Let's demonstrate our previous example with little modification.
SELECT
first_name,
last_name,
department_id,
salary,
SUM(salary) OVER(PARTITION BY department_id) as sum_salary_department_wise
FROM employees ;

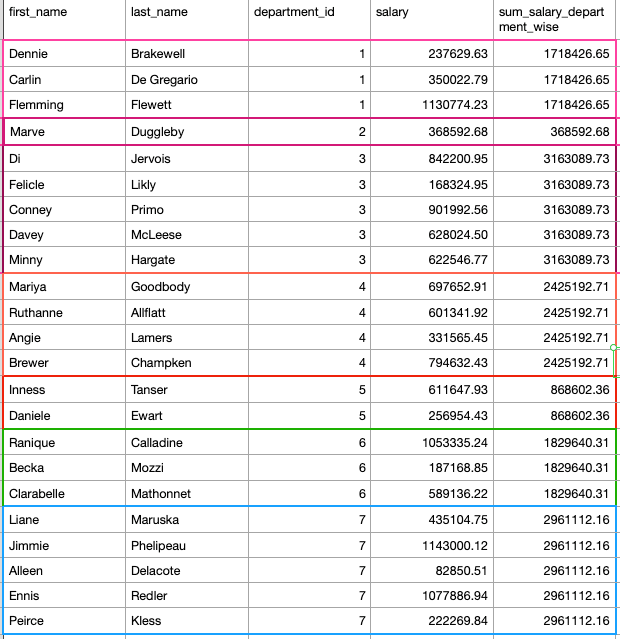
As you can see in the image of the output above, we tried getting the sum of the salary of each employee in that department. In the above image, for each employee, this query returns its first_name, last_name, department_id, salary, and sum_salary_department_wise which denotes, the sum of all the salaries for each department.
Next, One last demonstration of finding the maximum salary and minimum salary of each department along with employee and their salary.
SELECT
first_name,
last_name,
department_id,
salary,
MIN(salary) OVER(PARTITION BY department_id) as minimum_department_salary,
MAX(salary) OVER(PARTITION BY department_id) as maximum_department_salary
FROM employees;

In the above output, we can see the partitioning of rows done by PARTITION BY part of the OVER() clause. This returns us the required individual columns along with the minimum_department_salary and maximum_department_salary which denotes the minimum and maximum salary for their departments.
Now we want to further segregate the salary based on gender in each department. We need the maximum salary and minimum salary of the employees in department_id = 3, for each gender along with employee data.
SELECT
first_name,
last_name,
department_id,
salary,
gender,
MIN(salary) OVER(PARTITION BY department_id, gender) as minimum_department_salary,
MAX(salary) OVER(PARTITION BY department_id, gender) as maximum_department_salary
FROM employees
WHERE department_id = 3;

In the above query and the output, we partitioned or grouped by both department_id and gender columns. This returns us the required individual rows along with the minimum salary and maximum salary of the department and gender. We can see that the minimum salary and maximum salary are different for the genders although they are in the same department as mentioned in the query's where clause.
Similarly, other aggregate functions like COUNT(), AVG(), etc. can be used. In the next series, we will be looking at using ranking or analytical functions with PARTITION BY soon.